
TECH
What is Data Science? Beginner’s Guide
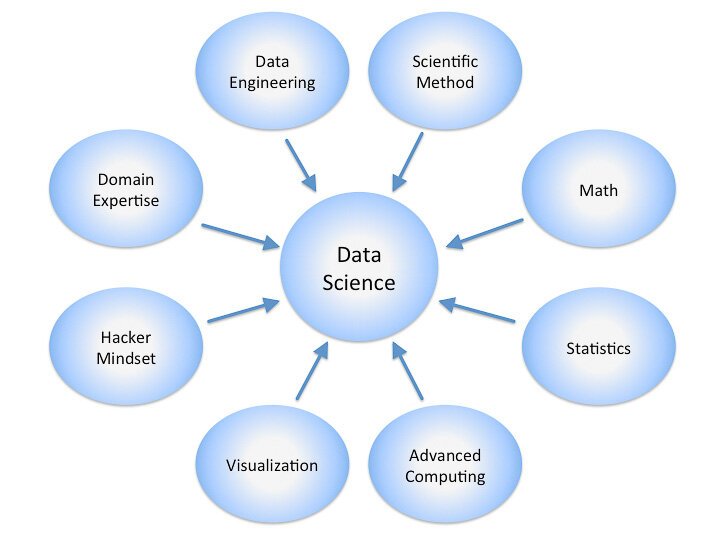
The wide field of records science is concerned with deriving knowledge and insights from organized and unstructured information. It blends domain-specific knowledge with skills from computer science and data to examine, understand, and present complex statistics sets.
Students who enroll in a data science course get an understanding of fundamental concepts like machine learning, programming, and data visualization.
These programs supply students with the necessary equipment to resolve problems, find patterns in big datasets, and make knowledgeable judgments. Anyone interested in a career in this fascinating field should take the Data Science course.
The need for workers proficient in technology is growing as more organizations rely on projects driven by data.
Major Components of Data Science
Among many other academic disciplines, computer programming, statistics, machine learning, and data visualization are all included in the large field of data science. It involves determining the importance of the data.
Every procedure stage is covered, from obtaining data to guarantee accuracy to assessing it to spot patterns and trends. The ultimate goal is to maximize the firm’s reliance on the data.
Enthusiasts can explore the intricacies of this discipline by signing up for a data science course. Let’s look at the key components that comprise the data science framework.
Data Collection and Acquisition
The fundamental component of any Data Science course is data. This first stage is the careful collection of relevant data from various sources. The statistics may also come from semi-structured APIs, unstructured social media posts, or established databases. The capacity to locate, reap, and deal with this information is refined in an intensive path on data science.
Professionals need to understand the nuances of data collection. They learn to recognize biases, evaluate the data’s quality, and select the most effective retrieval methods. The quantity and quality of data are equally important at this stage because the inferences that can be drawn later on are greatly influenced by the data’s integrity.
Data Mining
Data mining is essentially the process of using one or more software tools to evaluate patterns in large volumes of data. It can be applied in many fields, including science and research. Businesses can use data mining to leverage customer information to gain deeper insights, create deeper connections, and optimize resource allocation.
Data Engineering
Data engineering’s primary goal is to create software solutions for data issues requiring the setup of data systems with endpoints and pipelines. Data engineering needs a deep understanding of various data technologies and frameworks and the ability to develop data solutions to support business processes.
Data Visualisation
Effective communication of findings is a crucial competency for a talented data scientist. An essential factor in communicating complex thoughts, understandably is data visualization. Students who enroll in a data science course learn how to use visualization equipment to supply appealing portraits that efficiently convey data-driven narratives.
Choosing the best visualization kind for the statistics and the message you need to explicit is an essential step in generating effective statistics visualization, which goes beyond virtually making visually attractive charts. This capability is important when presenting findings to stakeholders who may not have a technical background.
Big Data Technologies
Data scientists want to be professional at working with big statistics because of the massive variety of information generated these days. Working with frameworks for disbursed computing is a part of this.
Data Science course modules frequently blanket big information technologies, which help students scale their research to manipulate massive datasets successfully.
To completely utilize the available records, one must have a solid knowledge of huge information technology. It opens the door to extra in-depth investigations by enabling data scientists to work with datasets that are more extensive than those supported through conventional computer platforms.
Machine learning
Machine Learning is the data science department that uses distinct algorithms to perform on big volumes of data accrued and extracted from numerous resources, permitting the gadget to deal with datasets autonomously without human intervention.
It forecasts, analyses patterns, and provides advice. Fraud detection and consumer retention are two common applications of machine learning.
A social media platform is a fantastic place to see machine learning in action, as users’ behaviour is gathered using rapid and effective algorithms to offer multimedia files, articles, and much more, depending on their interests.
Machine learning is another branch of artificial intelligence that uses a range of techniques and algorithms to acquire the required knowledge.
Exploratory Data Analysis
After cleaning and preparing the statistics, exploratory data analysis is completed. Finding and understanding the correlations, styles, and traits in the data is the primary goal in this situation.
In a Data Science course, college students research statistical techniques and visualization equipment that are valuable resources in pattern recognition. Analyzing exploratory records is essential as it establishes the foundation for formulating theories and identifying traits that can be huge for modelling.
This is the section where data scientists study the tale the data tells and provide essential context for additional studies.
Artificial Intelligence
The purpose of Artificial intelligence is to allow software programs to observe and examine their environment via machine learning models that perceive patterns or predefined guidelines and search engines, after which they make choices primarily based on those tests.
Artificial intelligence tries to mimic biological intelligence to decrease manual human intervention for several duties. As a result, the system or software can perform with special degrees of autonomy.
Career Opportunities of Data Science Course
Within the ever-evolving field of data science, numerous key positions have developed, all of which can be critical to using data. Leading the charge in extracting actionable insights from complex datasets is the field of data science.
The production of algorithms through Machine learning engineers improves automation and prediction models. The infrastructure required for generation era and storage is built via data engineers. Data is transformed into strategic enterprise selections by business intelligence analysts.
For these roles, a competitive coding course is required. For jobs like statistics scientists and machine learning engineers, one must be talented in algorithms and coding. Professionals may be a part of an aggressive coding school to gain the problem-solving abilities required in a competitive work marketplace.
Enhancing algorithmic reasoning increases performance and productivity in data-driven jobs. Competent coding abilities combined with unique work ensure that human beings remain adaptable and capable in this fast-paced place, especially because the need for data science knowledge increases.
Conclusion
In our data-driven world, data science is the revolutionary force driving insights, innovation, and well-informed decision-making.
A thorough examination of the fundamental ideas, tools and methods needed to successfully navigate the ever-evolving field of data analysis was given in the Data Science course.
This course equips students to succeed in the ever-evolving field of data science and acts as a catalyst for a future powered by data.

Helonia Neue is a contemporary sans-serif typeface that balances geometric precision with humanist warmth. It is designed for versatility, making it a suitable choice for both digital and print applications. The font’s clean, structured letterforms enhance readability and visual appeal.
Typography plays a crucial role in design, influencing how messages are perceived. Helonia Neue is crafted to deliver clarity and impact, making it ideal for modern branding and digital experiences. Its structure ensures elegance while maintaining functionality in various design contexts.
Unlike rigid geometric fonts, Helonia Neue incorporates subtle curves, making it feel more natural and approachable. This balance allows it to work well across different industries, from corporate branding to creative projects.
The demand for fonts that maintain readability across screens has grown. Helonia Neue meets this need by offering well-defined letter spacing and open apertures, ensuring text remains legible at various sizes.
Helonia Neue: A Typeface Designed for Modern Creativity
Helonia Neue is a contemporary sans-serif font known for its clean, geometric structure and subtle humanist curves. It is designed to be highly versatile and readable, making it suitable for branding, digital interfaces, and print materials. With its well-balanced letterforms and open spacing, it ensures clarity in both small and large text sizes.
Unlike many traditional fonts, Helonia Neue adapts effortlessly to various design needs, from corporate identity to creative projects. Its multiple weights and styles allow designers to create strong visual hierarchies, making it a top choice for modern typography. Whether used for headlines, body text, or signage, it provides a polished and professional look.
Design Aesthetic of Helonia Neue
The design of Helonia Neue follows a minimalist yet expressive approach. It avoids unnecessary complexity while incorporating small details that enhance its overall appearance. The result is a font that looks modern, refined, and timeless.
One of the key features is its geometric foundation. Letters have a balanced proportion, which provides uniformity when used in large blocks of text. However, the slight curvature in certain strokes ensures that it does not feel too rigid or mechanical.
Another important design element is its consistent x-height. This improves readability, especially in body text, by ensuring uniformity across different words and characters. The spacing between letters is well-calculated, making it an excellent choice for both headlines and paragraphs.
Helonia Neue’s design also makes it highly adaptable. It retains clarity in bold, italic, and lighter versions, allowing designers to create distinct typographic hierarchies. This makes it a go-to font for branding, web design, and editorial projects.
Key Features of Helonia Neue
Helonia Neue offers a variety of features that make it stand out among other sans-serif fonts. These features improve both its functionality and aesthetic appeal, making it a popular choice among designers.
Some of its most notable characteristics include:
- Multiple weights and styles – Available in Thin, Light, Regular, Medium, Bold, and Black.
- Excellent readability – Open apertures and well-defined strokes ensure clarity across all sizes.
- Multilingual support – Covers a wide range of characters, making it useful for global branding.
- Scalable and adaptable – Works equally well in small mobile interfaces and large display formats.
Comparison of Helonia Neue with Other Popular Fonts
| Feature | Helonia Neue | Helvetica | Montserrat | Gotham |
| Readability | High | Moderate | High | Moderate |
| Geometric Design | Balanced | Strong | Decorative | Compact |
| Multilingual Support | Yes | Limited | Yes | Yes |
| Ideal Use Cases | Branding, Web, Editorial | Corporate, Formal | Creative, Digital | Advertising, Bold Branding |
Unlike Helvetica, which can sometimes feel too neutral, Helonia Neue offers a modern yet distinctive touch. Compared to Montserrat, it has less decorative elements, making it a more versatile option.
Best Use Cases for Helonia Neue
Helonia Neue is a multi-purpose typeface that can be effectively used in various design projects. Its adaptability makes it a top choice for both formal and creative applications.
For branding and logo design, it creates a professional and modern identity. Many companies prefer it due to its clean, contemporary look that works well across marketing materials. The different font weights allow for customization in brand representation.
Web designers use Helonia Neue for user interfaces and websites. It offers excellent legibility on screens and pairs well with both serif and sans-serif fonts. Its open structure ensures that text remains readable, even in smaller sizes.
The font is also ideal for editorial and print design. Whether used in magazines, brochures, or corporate reports, it maintains a balance between elegance and clarity. Designers appreciate its ability to blend into both minimalist layouts and visually rich compositions.
For signage and wayfinding, Helonia Neue’s bold and high-contrast versions ensure that text is easily readable from a distance. It is frequently used in airports, shopping centers, and public transportation systems.
Why Designers Prefer Helonia Neue
Many designers choose Helonia Neue because it offers the best of both worlds – modernity and functionality. Unlike overly stylized fonts, it remains highly versatile across different industries.
One of the biggest advantages is its scalability. Whether used in small digital elements like app buttons or large outdoor billboards, it retains its clarity and sharpness. This makes it a highly practical font for various commercial applications.
Another reason for its popularity is its timeless appeal. While many fonts trend for a while and then fade away, Helonia Neue maintains a classic yet contemporary aesthetic that makes it relevant for years to come.
The ability to pair it with both serif and sans-serif fonts also adds to its usability. Designers often combine it with serif fonts for contrast or use it alongside other sans-serifs for a consistent look.
How to Use Helonia Neue Effectively
Using Helonia Neue effectively requires understanding the right weights and pairings. Different font weights serve different design needs, making it essential to select the correct one for the intended purpose.
- Thin & Light – Best for luxury branding and elegant design concepts.
- Regular & Medium – Ideal for body text in web and print media.
- Bold & Black – Perfect for headlines, logos, and emphasis text.
Font Pairing Suggestions
| Helonia Neue Weight | Best Font Pairing |
| Light & Regular | Playfair Display (Serif) |
| Medium & Bold | Open Sans (Sans-Serif) |
| Black | Roboto Slab (Serif) |
Choosing the right color contrast also enhances readability. Helonia Neue works best in high-contrast color schemes, such as black text on a white background or light text on dark backgrounds for digital interfaces.
Conclusion
Helonia Neue is a modern, versatile, and highly readable typeface that caters to a wide range of design needs. Whether used for branding, editorial content, or digital interfaces, it provides clarity and sophistication.
Its balanced proportions, clean design, and multiple weight options make it a go-to font for designers seeking flexibility. Its ability to blend well with different design styles ensures long-term usability.
With its geometric yet humanist approach, Helonia Neue stands out as a font that maintains professionalism while adding visual warmth. It is a valuable asset in any designer’s toolkit, offering both style and practicality.
FAQs
What makes Helonia Neue different from other sans-serif fonts?
Helonia Neue combines geometric structure with soft curves, making it both modern and highly readable across various applications.
Is Helonia Neue suitable for both digital and print design?
Yes, it is optimized for screens and printed materials, ensuring clarity and consistency in any format.
What are the best use cases for Helonia Neue?
It is perfect for branding, web design, editorial layouts, signage, and corporate materials due to its versatility.
Can Helonia Neue be used for multilingual projects?
Yes, it supports a wide range of languages and characters, making it ideal for global design needs.
Where can I get Helonia Neue for my projects?
It is available on font marketplaces and official typography websites, with licensing options for different uses.

The PR-AD-48-760-35ZMHY is a modern motorized drive roller designed for industrial conveyor systems. It provides efficient movement of goods without requiring external motors or chains. This makes it a space-saving and cost-effective solution for various industries.
With the increasing demand for automated material handling, businesses are looking for smart, reliable, and energy-efficient conveyor solutions. The PR-AD-48-760-35ZMHY offers a smooth, controlled, and low-noise operation, improving workplace efficiency.
Its 48V DC power ensures a strong torque output while maintaining energy efficiency. This allows it to transport heavy loads without excessive power consumption. The roller is widely used in logistics, manufacturing, and warehouse automation.
Industries that require continuous and precise product movement benefit from this advanced roller system. Unlike traditional rollers, it eliminates belt slippage issues and minimizes maintenance costs.
PR-AD-48-760-35ZMHY – A Smart Solution for Modern Conveyors
The PR-AD-48-760-35ZMHY is a high-performance motorized drive roller designed for efficient material handling in industrial conveyor systems. It operates on 48V DC power, providing smooth, controlled movement without the need for external motors, belts, or chains. This makes it an energy-efficient and space-saving solution, reducing operational costs while ensuring seamless automation.
Unlike traditional rollers, the PR-AD-48-760-35ZMHY delivers consistent speed, high torque, and low-noise operation, making it ideal for warehousing, logistics, manufacturing, and e-commerce industries. Its durability and low maintenance requirements make it a reliable choice for businesses seeking long-term efficiency and safety in their conveyor systems.
Key Features of PR-AD-48-760-35ZMHY
The PR-AD-48-760-35ZMHY is known for its high-performance motor, which delivers consistent speed and smooth acceleration. It ensures that products move steadily without sudden stops or jolts.
One of its standout features is energy efficiency. The roller consumes less power while handling heavy loads, reducing operational costs over time. Its compact design also makes it easy to install in conveyor systems with limited space.
Additionally, the roller is designed for low-noise operation. Unlike traditional chain-driven rollers that produce loud vibrations, this motorized drive roller operates quietly, making it ideal for workplaces where noise reduction is essential.
Its durability ensures a long lifespan with minimal wear and tear. The internal components are protected from dust and moisture, reducing the risk of breakdowns.
Applications of PR-AD-48-760-35ZMHY
The PR-AD-48-760-35ZMHY is widely used in the manufacturing industry to transport materials and components between workstations. It helps improve production efficiency by ensuring smooth and automated movement.
In logistics and warehousing, it plays a key role in sorting and distributing goods. Automated conveyor systems equipped with this roller can handle large volumes of packages without manual intervention.
E-commerce businesses also benefit from this motorized drive roller. It ensures seamless product movement, reducing delays in packaging and shipping processes. This leads to faster order fulfillment and improved customer satisfaction.
The food and pharmaceutical industries use this roller for safe and sanitary transport of products. Since it operates with precision, it helps maintain strict quality standards by preventing product damage.
Advantages Over Traditional Conveyor Systems
The PR-AD-48-760-35ZMHY outperforms traditional conveyor rollers in multiple ways. It eliminates the need for external belts and gear motors, reducing maintenance costs and mechanical failures.
Unlike traditional rollers, which consume higher power, this 48V DC motorized roller offers energy-efficient operation. This leads to significant cost savings, especially for businesses with high conveyor usage.
It also ensures better load handling, accommodating both lightweight and heavy items without performance issues. The smooth acceleration and deceleration prevent sudden movements that could damage fragile products.
Another major advantage is workplace safety. Traditional rollers often have exposed moving parts, which increase the risk of accidents. This motorized roller, however, is fully enclosed, making it safer for workers.
Comparison Between PR-AD-48-760-35ZMHY & Traditional Rollers
| Feature | PR-AD-48-760-35ZMHY | Traditional Conveyor Rollers |
| Power Efficiency | High | Moderate |
| Noise Level | Low | High |
| Maintenance | Low | High |
| Load Capacity | High | Medium |
| Safety | Enclosed design | Exposed moving parts |
How to Install PR-AD-48-760-35ZMHY
Installing the PR-AD-48-760-35ZMHY is a straightforward process. Before starting, it is essential to check the power requirements and conveyor compatibility. The roller is designed to fit most modern conveyor systems.
The first step is to position the roller in the conveyor frame. It should be aligned properly to ensure even weight distribution and avoid misalignment issues during operation.
Next, the electrical wiring must be connected securely to the power source. Since it operates on 48V DC, it is important to use the correct voltage settings to avoid any damage.
Once the installation is complete, it is recommended to test the roller by running it at a low speed. This helps detect any issues with movement or power fluctuations before full-scale operation.
Maintenance Tips for Long-Term Performance
Regular inspection and maintenance can extend the lifespan of the PR-AD-48-760-35ZMHY. One of the most important maintenance tasks is checking for wear and tear on the roller surface.
Dust and debris can accumulate over time, affecting performance. Periodic cleaning and lubrication help maintain smooth operation. It is advisable to use approved lubricants to prevent internal component damage.
Electrical connections should also be inspected regularly. Loose connections or voltage fluctuations can cause performance issues. Ensuring proper wiring reduces the risk of operational failures.
If the roller starts making unusual noises or vibrations, it may indicate a mechanical issue. Troubleshooting early can prevent costly breakdowns and improve efficiency.
Future Innovations & Trends in Conveyor Technology
With advances in technology, motorized drive rollers like PR-AD-48-760-35ZMHY are evolving to become smarter and more efficient. Future versions are expected to integrate AI-based monitoring for real-time performance analysis.
IoT-enabled rollers will allow remote tracking of conveyor system efficiency. This will help in predictive maintenance, reducing unexpected downtime. Businesses can plan servicing before major breakdowns occur.
Energy-saving innovations are also on the rise. Manufacturers are working on ultra-low power rollers that can further cut down electricity usage while maintaining high performance.
Wireless and battery-operated conveyor rollers are being explored. These would eliminate the need for direct electrical connections, allowing more flexibility in conveyor system layouts.
Conclusion
The PR-AD-48-760-35ZMHY is a cutting-edge motorized drive roller that improves efficiency, reduces maintenance, and ensures smooth product movement. It is widely used in manufacturing, logistics, e-commerce, and pharmaceutical industries.
Its energy-efficient 48V DC operation makes it an ideal choice for businesses looking to cut costs while maintaining high performance. Compared to traditional conveyor rollers, it offers better load capacity, low noise, and increased safety.
With proper installation and maintenance, this motorized roller can provide long-term reliability. Its compact design makes it suitable for both new and existing conveyor systems.
As technology advances, future smart conveyor rollers will integrate AI, IoT, and wireless capabilities, making material handling even more efficient and automated. Businesses investing in this technology will gain a competitive edge in automation and logistics.
FAQs
What makes PR-AD-48-760-35ZMHY better than traditional rollers?
It operates on 48V DC power, offering high torque, low energy consumption, and smooth movement without external motors or chains.
Where is PR-AD-48-760-35ZMHY commonly used?
It is widely used in logistics, e-commerce, manufacturing, warehousing, and pharmaceutical industries for automated material handling.
Does PR-AD-48-760-35ZMHY require frequent maintenance?
No, it has a durable design with minimal wear and tear, requiring only periodic cleaning and inspections for optimal performance.
How does PR-AD-48-760-35ZMHY improve workplace safety?
Its fully enclosed design eliminates exposed moving parts, reducing accident risks while ensuring smooth and controlled movement.
Can PR-AD-48-760-35ZMHY handle heavy loads efficiently?
Yes, it provides high torque output, allowing it to transport both lightweight and heavy products without performance issues.

The DieHard Boat Motor 48858615 is an electric trolling motor known for its reliability and durability. It was widely used by boat owners for fishing and recreational boating. This motor was part of the DieHard brand, which is primarily recognized for automotive batteries.
DieHard ventured into marine motors through a collaboration with manufacturers like Minn Kota. This ensured that their products met the high standards required for boat propulsion. The DieHard Boat Motor 48858615 was mainly available through Sears, which distributed various DieHard-branded equipment.
Trolling motors like this one are essential for small to medium-sized boats. They provide quiet and efficient movement, making them ideal for fishing. Instead of relying on noisy gas-powered motors, electric trolling motors allow for precise control.
Even though this model is no longer in production, it remains a popular choice among boaters who prefer older, well-built motors. Many users still seek information about maintenance and replacement parts to keep their DieHard Boat Motor 48858615 operational.
Background and Manufacturer Information
The DieHard brand was primarily known for producing high-quality automotive batteries. However, it also expanded into marine products, including trolling motors. The DieHard Boat Motor 48858615 was one of the key models designed for small watercraft.
It is believed that DieHard motors were manufactured by Minn Kota, a well-established company in the marine industry. Many features of this motor are similar to Minn Kota models from the same time period, supporting this connection.
Sears was the primary retailer for the DieHard Boat Motor 48858615. During the late 1980s and 1990s, Sears offered a range of boating accessories, and these motors were among the most popular choices for budget-conscious boaters.
Even though Sears no longer sells these motors, enthusiasts still look for them in second-hand markets. Some owners continue to restore them due to their solid construction and dependable performance on the water.
Technical Specifications of DieHard 48858615
The DieHard Boat Motor 48858615 is an electric trolling motor with a transom-mount design. It was built for easy installation and control, making it user-friendly for both beginners and experienced boaters.
This motor typically operates on a 12-volt or 24-volt battery system, depending on the variant. The thrust power is moderate, suitable for small to medium boats used for fishing or casual boating.
Key Technical Details:
- Motor Type: Electric trolling motor
- Battery Requirement: 12V or 24V
- Mounting Style: Transom mount
- Propeller System: Two or three-blade design
- Thrust Power: Suitable for small to medium boats
The construction is designed for freshwater use, but some models can handle light saltwater exposure. However, users must rinse the motor thoroughly after saltwater use to prevent corrosion.
Many of these motors have speed control settings that allow for precise maneuvering. This makes them excellent for slow trolling, a common fishing technique that requires minimal boat disturbance.
Features and Benefits
One of the best aspects of the DieHard Boat Motor 48858615 is its durability. Built with high-quality materials, this motor can last for years with proper maintenance. Many boaters still use these motors today due to their long lifespan.
The motor is designed for quiet operation, which is essential for fishing. Loud motors can scare away fish, but an electric trolling motor allows for smooth, silent movement in the water.
Another major benefit is its ease of use. The DieHard Boat Motor 48858615 features a simple tiller handle for steering and speed adjustment. Even those new to boating can operate it without difficulty.
This motor is also energy-efficient. Unlike gas-powered engines, an electric trolling motor consumes minimal power, allowing for extended use on a single battery charge. It provides steady thrust without excessive energy consumption.
Common Uses and Applications
The DieHard Boat Motor 48858615 is widely used for small recreational boats. Its compact size and reliable power make it ideal for fishing boats, dinghies, and kayaks that require steady, low-speed propulsion.
Fishermen prefer this motor due to its quiet operation. It allows them to navigate shallow waters without disturbing fish, making it perfect for lakes and rivers. Many fishing boats rely on trolling motors like this for slow, controlled movements.
Some people use this motor for small personal boats or inflatables. It provides a convenient alternative to paddling, especially for those who enjoy casual lake cruising or exploring narrow waterways.
Although primarily designed for freshwater use, some boaters have used it in light saltwater conditions. However, it requires extra care, such as frequent cleaning and corrosion prevention, to maintain performance.
How to Install and Operate
Installing the DieHard Boat Motor 48858615 is straightforward. It features a transom-mount system, which means it attaches to the back of the boat. The mounting bracket ensures a secure fit.
Basic Installation Steps:
- Attach the motor to the transom using the mounting clamp
- Connect the battery cables to the power source (12V or 24V)
- Adjust the shaft length for proper depth in the water
- Secure the tiller handle in a comfortable position
Operating the motor is simple. The tiller handle is used to control speed and direction. Most models have multiple speed settings, allowing for gradual acceleration or deceleration.
Before heading out on the water, it’s essential to check the battery charge. A fully charged battery ensures longer operation time and prevents power loss while boating.
Maintenance and Care Tips
Proper maintenance is key to ensuring the DieHard Boat Motor 48858615 runs efficiently. Regular cleaning and inspection can extend its lifespan and prevent performance issues.
After each use, rinse the motor with fresh water, especially if it has been exposed to saltwater. This helps prevent corrosion and buildup on the motor’s components.
Checking the propeller is also important. Remove debris such as fishing lines or weeds that may get tangled in the blades. A clogged propeller can reduce efficiency and strain the motor.
Battery maintenance is another crucial aspect. Always use a high-quality marine battery and charge it fully before each trip. Proper battery care ensures smooth performance and avoids sudden power loss on the water.
Conclusion
The DieHard Boat Motor 48858615 remains a reliable and well-built trolling motor. Even though it is no longer in production, many boaters continue to use and maintain these motors due to their durability and efficiency.
With quiet operation and easy handling, this motor is an excellent choice for fishing and small boat navigation. Its energy-efficient design allows for extended use, making it a practical option for recreational boaters.
Finding replacement parts can be a challenge, but with proper maintenance, these motors can last for many years. Many owners appreciate the simple and effective design that provides consistent performance.
Overall, the DieHard Boat Motor 48858615 is a valuable addition to any small boat, offering a balance of power, control, and reliability. Those who own one should ensure regular care to keep it in excellent condition for future use.
FAQs
Is the DieHard Boat Motor 48858615 still available for purchase?
No, it is discontinued, but you may find used models on online marketplaces or boating forums.
What type of battery does the DieHard Boat Motor 48858615 require?
It typically runs on a 12V or 24V deep-cycle marine battery for efficient performance.
Can this motor be used in saltwater?
It is mainly designed for freshwater, but with proper cleaning and maintenance, it can handle light saltwater use.
Where can I find replacement parts for this motor?
Spare parts can sometimes be found on eBay, marine supply stores, or through Minn Kota-compatible components.
How do I prevent corrosion on my DieHard Boat Motor 48858615?
Rinse it with fresh water after every use, apply anti-corrosion spray, and store it in a dry place.
Heavy Equipment Overhaul Checklist

Apex Traffic vs ClickSEO: How to Use Both for Instant and Long-Term Website Success

Augie Martinez Lehigh: Transforming Student-Athletes with Leadership and Sports Excellence

Helonia Neue: How This Font Enhances Readability Across Web, Branding, and Editorials

PR-AD-48-760-35ZMHY: A Smart, Cost-Effective Solution for Automated Product Movement

Start Post GravityInternet.net: A Complete Walkthrough from Signup to Publishing Your First Post

Crypto30x.com Zeus: The Ultimate AI-Powered Trading Bot for Smarter Cryptocurrency Investments

Belichick Prescott Cowboys Turnaround: The Game-Changing Impact on Dallas

Luther Social Media Maven Keezy.co: The Ultimate Growth Strategy for Brands

DieHard Boat Motor 48858615: Complete Guide to Features and Maintenance
Heavy Equipment Overhaul Checklist
Apex Traffic vs ClickSEO: How to Use Both for Instant and Long-Term Website Success
Augie Martinez Lehigh: Transforming Student-Athletes with Leadership and Sports Excellence
Helonia Neue: How This Font Enhances Readability Across Web, Branding, and Editorials
PR-AD-48-760-35ZMHY: A Smart, Cost-Effective Solution for Automated Product Movement
Start Post GravityInternet.net: A Complete Walkthrough from Signup to Publishing Your First Post
Crypto30x.com Zeus: The Ultimate AI-Powered Trading Bot for Smarter Cryptocurrency Investments
Belichick Prescott Cowboys Turnaround: The Game-Changing Impact on Dallas
Luther Social Media Maven Keezy.co: The Ultimate Growth Strategy for Brands
DieHard Boat Motor 48858615: Complete Guide to Features and Maintenance
Heavy Equipment Overhaul Checklist
Apex Traffic vs ClickSEO: How to Use Both for Instant and Long-Term Website Success
Augie Martinez Lehigh: Transforming Student-Athletes with Leadership and Sports Excellence
Helonia Neue: How This Font Enhances Readability Across Web, Branding, and Editorials
PR-AD-48-760-35ZMHY: A Smart, Cost-Effective Solution for Automated Product Movement
Start Post GravityInternet.net: A Complete Walkthrough from Signup to Publishing Your First Post
Crypto30x.com Zeus: The Ultimate AI-Powered Trading Bot for Smarter Cryptocurrency Investments
Belichick Prescott Cowboys Turnaround: The Game-Changing Impact on Dallas
Luther Social Media Maven Keezy.co: The Ultimate Growth Strategy for Brands
DieHard Boat Motor 48858615: Complete Guide to Features and Maintenance
-
 L,IFESTYLE1 year ago
L,IFESTYLE1 year agoExploring the Heart of Iowa City Downtown District
-
 SPORTS2 years ago
SPORTS2 years agoclub america vs deportivo toluca f.c. timeline
-
CRYPTO2 years ago
Features of Liquidity Providers and Differences Between Them
-
 BUSINESS2 years ago
BUSINESS2 years agoThe Evolution of the Patagonia Logo: A Look at the Brand’s Iconic Emblem
-
 CRYPTO2 years ago
CRYPTO2 years agoThe Essential Cryptocurrency Laws By State
-
 TECH2 years ago
TECH2 years agoBuild Your Email Marketing Contact
-

 HEALTH4 months ago
HEALTH4 months agoProstavive Colibrim: A Natural Prostate Health Supplement
-
 TECH2 years ago
TECH2 years agoMaximizing Your Pixel 6a’s Wireless Charging Performance: Tips and Tricks